Introduction
Welcome to the Apache Arrow guide for the Rust programming language. This guide was created to help you become familiar with the Arrow crate and its functionalities.
What is Apache Arrow?
According to its website Apache Arrow is defined as:
A language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs. The Arrow memory format also supports zero-copy reads for lightning-fast data access without serialization overhead.
After reading the description you have probably come to the conclusion that Apache Arrow sounds great and that it will give anyone working with data enough tools to improve a data processing workflow. But that's the catch, on its own Apache Arrow is not an application or library that can be installed and used. The objective of Apache Arrow is to define a set of specifications that need to be followed by an implementation in order to allow:
- fast in-memory data access
- sharing and zero copy of data between processes
Fast in-memory data access
Apache Arrow allows fast memory access by defining its in-memory columnar format. This columnar format defines a standard and efficient in-memory representation of various datatypes, plain or nested (reference).
In other words, the Apache Arrow project has created a series of rules or specifications to define how a datatype (int, float, string, list, etc.) is stored in memory. Since the objective of the project is to store large amounts of data in memory for further manipulation or querying, it uses a columnar data definition. This means that when a dataset (data defined with several columns) is stored in memory, it no longer maintains its rows representation but it is changed to a columnar representation.
For example, lets say we have a dataset that is defined with three columns named: session_id, timestamp and source_id (image below). Traditionally, this file should be represented in memory maintaining its row representation (image below, left). This means that the fields representing a row would be kept next to each other. This makes memory management harder to achieve because there are different datatypes next to each other; in this case a long, a date and a string. Each of these datatypes will have different memory requirements (for example, 8 bytes, 16 bytes or 32 bytes).

By changing the in memory representation of the file to a columnar form (image above, right), the in-memory arrangement of the data becomes more efficient. Similar datatypes are stored next to each other, making the access and columnar querying faster to perform.
Sharing data between processes
Imagine a typical workflow for a data engineer. There is a process that is producing data that belongs to a service monitoring the performance of a sales page. This data has to be read, processed and stored. Probably the engineer would first set a script that is reading the data and storing the result in a CSV or Parquet file. Then the engineer would need to create a pipeline to read the file and transfer the data to a database. Once the data is stored some analysis is needed to be done on the data, maybe Pandas is used to read the data and extract information. Or, perhaps Spark is used to create a pipeline that reads the database in order to create a stream of data to feed a dashboard. The copy and convert process may end up looking like this:
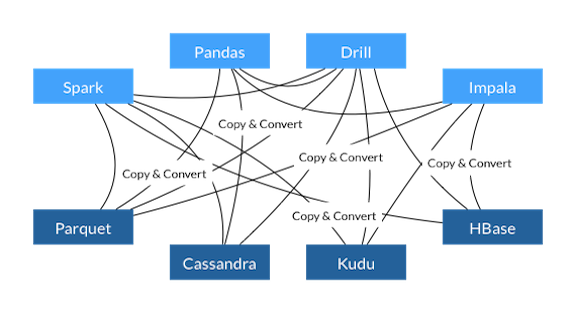
As it can be seen, the data is copied and converted several times. This happens every time a process needs to query the data.
By using a standard that all languages and processes can understand, the data doesn't need to be copied and converted. There can be a single in-memory data representation that can be used to feed all the required processes. The data sharing can be done regarding the language that is used.
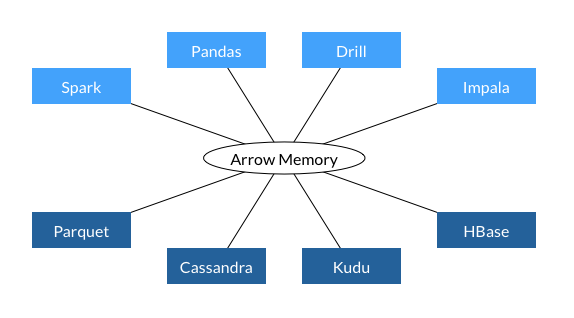
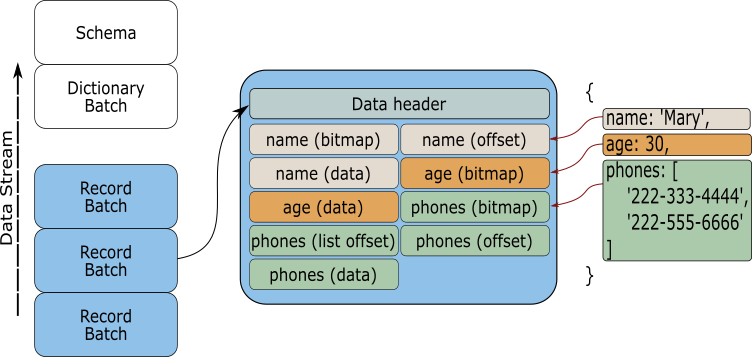
And thanks to this standardization the data can also be shared with processes that don't share the same memory. By creating a data server, packets of data with known structure (RecordBatch) can be sent across computers (or pods) and the receiving process doesn't need to spend time coding and decoding the data to a known format. The data is ready to be used once its being received.
The Rust Arrow crate
These and other collateral benefits can only be achieved thanks to the work done by the people collaborating in the Apache Arrow project. By looking at the project github page, there are libraries for the most common languages used today, and that includes Rust.
The Rust Arrow crate is a collection of structs and implementations that define all the elements required to create Arrow arrays that follow the Apache Arrow specification. In the next sections the basic blocks for working with the crate will be discussed, providing enough examples to give you familiarity to construct, share and query Arrow arrays.